When I wrangled the Current Reservoir Levels data set, I left all the values in one column and I didn’t feel comfortable with it. I realize after playing around a little more that while it is possible to subset the column and select only the data I want, it’s less than ideal to do this constantly.
This is the head() of the data set after my previous wrangling:
| Date | Reservoir | Measurement Type | Site | Value |
|---|---|---|---|---|
| 2017-11-01 | Ashokan | Storage | East | 65.36 |
| 2017-11-01 | Ashokan | Elevation | East | 577.86 |
| 2017-11-01 | Ashokan | Elevation | West | 36.34 |
| 2017-11-01 | Ashokan | Storage | West | 577.89 |
| 2017-11-01 | Ashokan | Release | NA | 18.00 |
| 2017-11-01 | Schoharie | Storage | NA | 12.92 |
Pivoting wider
Since I already confirmed with skimr::skim() and summary() that I don’t have any empty or NA values in my original data set, I won’t introduce any confusion by pivoting the Value column into discrete “Swiss cheese” columns for Storage, Elevation, and Release with lots of pivoted NA values.
I am in essence taking the monolithic Value column and stretching it wider into three columns that are the same height, but have the same amount of data shared across all of them. This looks very ugly if you’re manually skimming the data, but it’s trivial to ignore NA values for most calculations and analysis that we will want to do.
I will use the pivot_wider() function that complements pivot_longer(), taking the new column names from Measurement Type and the values from Values. Duplicates will exist when we build a pivot like this, so I will create a temporary row_number column variable to ensure that all rows are unique.
data <- data %>%
mutate(row_number = row_number()) %>%
pivot_wider(
names_from = 'Measurement Type',
values_from = 'Value'
) %>%
select(-row_number)
data %>%
head(40) %>%
kbl() %>%
kable_styling(font_size=12) %>%
scroll_box(height="15em")| Date | Reservoir | Site | Storage | Elevation | Release |
|---|---|---|---|---|---|
| 2017-11-01 | Ashokan | East | 65.36 | NA | NA |
| 2017-11-01 | Ashokan | East | NA | 577.86 | NA |
| 2017-11-01 | Ashokan | West | NA | 36.34 | NA |
| 2017-11-01 | Ashokan | West | 577.89 | NA | NA |
| 2017-11-01 | Ashokan | NA | NA | NA | 18.00 |
| 2017-11-01 | Schoharie | NA | 12.92 | NA | NA |
| 2017-11-01 | Schoharie | NA | NA | 1109.86 | NA |
| 2017-11-01 | Schoharie | NA | NA | NA | 0.00 |
| 2017-11-01 | Rondout | NA | 47.26 | NA | NA |
| 2017-11-01 | Rondout | NA | NA | 835.85 | NA |
| 2017-11-01 | Rondout | NA | NA | NA | 9.92 |
| 2017-11-01 | Neversink | NA | 30.74 | NA | NA |
| 2017-11-01 | Neversink | NA | NA | 1430.03 | NA |
| 2017-11-01 | Neversink | North | NA | NA | 38.90 |
| 2017-11-01 | Neversink | South | NA | NA | 0.00 |
| 2017-11-01 | Neversink | Conservation Flow | NA | NA | 0.00 |
| 2017-11-01 | Pepacton | NA | 116.60 | NA | NA |
| 2017-11-01 | Pepacton | NA | NA | 1264.45 | NA |
| 2017-11-01 | Pepacton | North | NA | NA | 51.70 |
| 2017-11-01 | Pepacton | South | NA | NA | 0.00 |
| 2017-11-01 | Pepacton | Conservation Flow | NA | NA | 0.00 |
| 2017-11-01 | Cannonsville | NA | 47.69 | NA | NA |
| 2017-11-01 | Cannonsville | NA | NA | 1112.87 | NA |
| 2017-11-01 | Cannonsville | NA | NA | NA | 97.30 |
| 2017-11-02 | Ashokan | East | 64.95 | NA | NA |
| 2017-11-02 | Ashokan | East | NA | 577.58 | NA |
| 2017-11-02 | Ashokan | West | NA | 36.82 | NA |
| 2017-11-02 | Ashokan | West | 578.59 | NA | NA |
| 2017-11-02 | Ashokan | NA | NA | NA | 11.00 |
| 2017-11-02 | Schoharie | NA | 13.28 | NA | NA |
| 2017-11-02 | Schoharie | NA | NA | 1111.05 | NA |
| 2017-11-02 | Schoharie | NA | NA | NA | 0.00 |
| 2017-11-02 | Rondout | NA | 47.32 | NA | NA |
| 2017-11-02 | Rondout | NA | NA | 835.94 | NA |
| 2017-11-02 | Rondout | NA | NA | NA | 9.92 |
| 2017-11-02 | Neversink | NA | 30.68 | NA | NA |
| 2017-11-02 | Neversink | NA | NA | 1429.90 | NA |
| 2017-11-02 | Neversink | North | NA | NA | 39.00 |
| 2017-11-02 | Neversink | South | NA | NA | 0.00 |
| 2017-11-02 | Neversink | Conservation Flow | NA | NA | 0.00 |
If you look at the first six entries for Ashokan on November 1st, 2017, you can see the Swiss cheese effect in the Storage, Elevation, and Release columns. At this point I am ready to start visualizing the data to clean it, look for outliers, and explore more generally, but I’ve run into a topical problem that will require more learning.
Limitations of static visualization
I can quickly manipulate the data myself at my computer using the ggplot2 library, but seeing for myself and showing in a blog post are very different. Since there are six reservoirs, three factors, and eight instances of multiple sites, and since ggplot2 only makes static images out of the box, it’s not practical to use it for demonstrating exploration of the data.
For instance, here’s a basic boxplot looking at the Release numbers by reservoir:
ggplot(data) +
geom_boxplot(
mapping=aes(
x=Reservoir,
y=Release
)
)
This is a useful look at the distributions, but this brings up a lot of questions that we can’t investigate with static graphics. Are the outliers for Schoharie and Rondout just really high, or are they bad data? Cannonsville and Ashokan also seem to have very wide distributions. Also, Pepacton and Neversink have multiple flow sites, these graphs hide variances between the sites.
Here’s Pepacton broken down by site:
ggplot(
subset(
data,
Reservoir %in% 'Pepacton'
& Site %in% c(
"North",
"South",
"Conservation Flow"
)
)
) +
geom_boxplot(
mapping=aes(
x=Site,
y=Release
)
)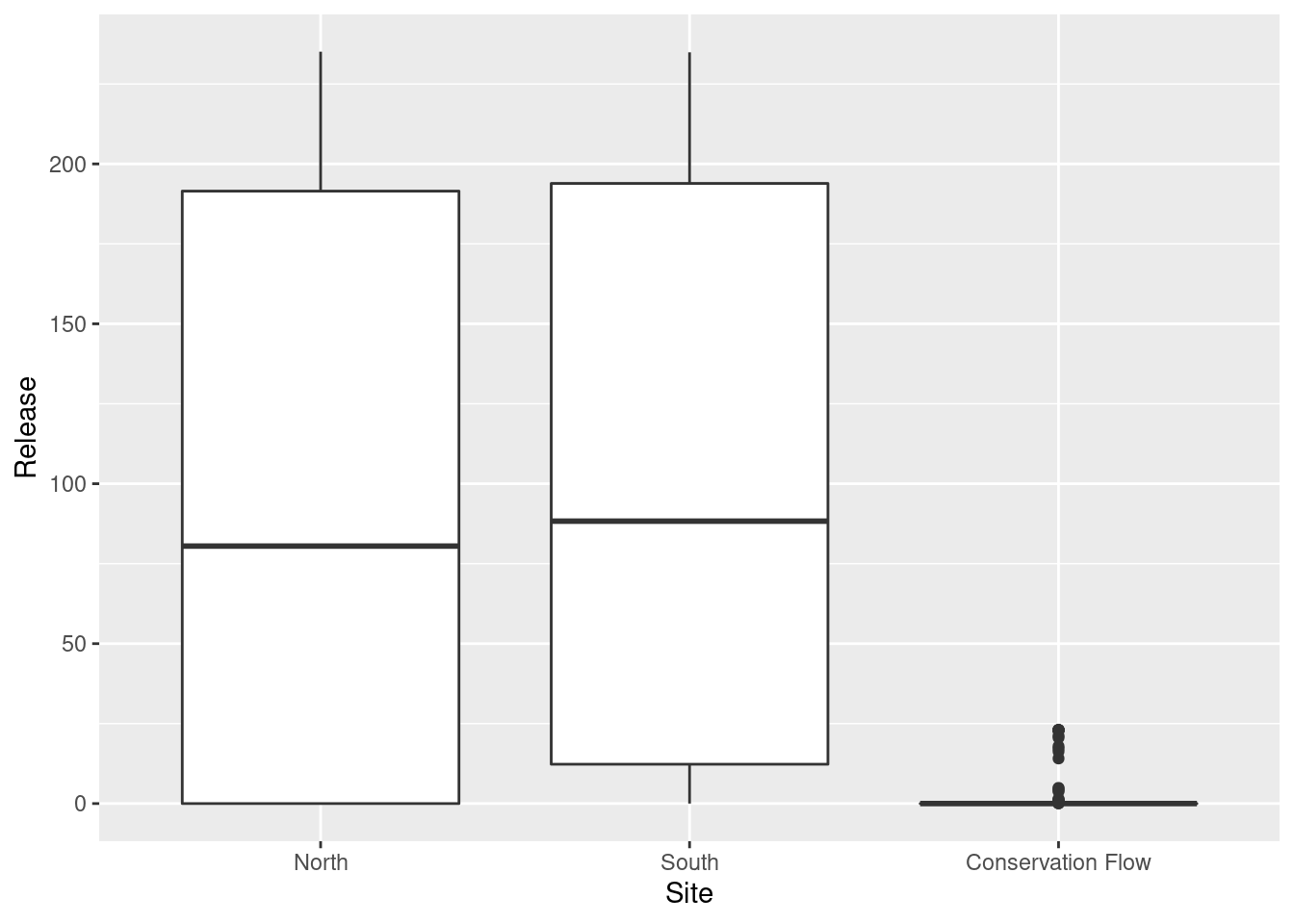
This gives us a more nuanced picture of those sites, but it’s not practical to explore the whole data set in a static environment. In order to make dynamic visualizations that will allow more interactivity with the data without requiring R to be installed on viewers’ local machines, I need to learn more about R’s dynamic visualization capabilities.
Visualization libraries and htmlwidgets
Much of R’s ability to use best-in-class visualization libraries comes from the htmlwidgets framework. I am still very much exploring new territory here, but I am already basically familiar with at least one of the widgets and libraries: DT, the library for making interactive tables with the DataTables library.
Here’s the Current Reservoir Levels as a DataTable along with some options customization:
data %>%
datatable(
caption = "Current Reservoir Levels",
filter = "top",
rownames = FALSE,
options = list(
pageLength = 10,
dom = 'Bftrp',
buttons = c("colvis", "csv", "excel")
),
extensions = c(
"Responsive",
"Buttons")
) %>%
DT::formatStyle(
columns = 0:5,
fontSize = '10pt')
What I’ve started learning about software packages and customization is that when you want something specific, you usually have to do it yourself by learning the underlying software. Most settings can’t be designed with every use-case in mind, so package maintainers often give the ability to interact with the underlying code, in this case JavaScript.
On this table, for instance, I would like to place the title at the top, the download and visibility buttons at the bottom, and shrink the size of the buttons since they’re massive. I was able to change the size of the table column font to 10 point, but the buttons, filter box, and other minor elements were not touched by this.
I prefer not to “give up” on visual presentation, but getting bogged down in obscure settings is a bad use of time. I’m also appreciating that there is a limit to how large of a dataset can be embedded in a page directly. I don’t understand the details of how the Current Reservoir Levels set is stored and accessed after it leaves my local computer, but the dataset is 1.8 megabytes.
That size isn’t prohibitive, but some of the sets I want to work with get into the gigabyte range, which is well beyond what’s necessary or acceptable for loading a modern page. I also appreciate now why most apps and dashboards are actually front ends to servers, and the reason for properties like loading only the portion of the data actively being used.
This also means that I have more studying and playing around with widgets to do. Even though the DataTables library is nice, tabular data is only the most basic way to display data. I am familiarizing myself with the available visualization libraries, and I have my work cut out for me.
I want to start small with more approachable packages, so my next goal is to do basic work with the Leaflet mapping library. I am still researching other packages, but I don’t want to go too far from best-in-class products. The more a library is used, the more likely that it will continue to be used and get updated and supported.
Smaller packages might have a specific feature, but if a package hasn’t been updated in five years there’s a good chance that it will break and become unfixable at some point unless I decide to fork it and take over. I’m not ready for that level of involvement, so I will stay closer to the crowd.
I looked at the list of htmlwidgets, and then compared their repositories with the repositories of the underlying libraries. I excluded packages where either the R binding or the base library have been neglected by the package maintainers for two years. This seems to be a decent shortlist for now:
- Plotly
ggiraphvisNetwork/vis.jsleaflet,tmap,mapview, andmapdeckfor mapping
And of course, all of the above can be turned into apps with shiny and dash, which I also want to learn. Onward!